 уже в Аспро.Cloud")

Привет, меня зовут Василий Ферапонтов, я директор по направлению SaaS-разработки в IT-компании Аспро. Мы создаем собственный продукт — систему управления бизнесом Аспро.Cloud.
Во время разработки продукта мы столкнулись с несколькими проблемами. Каждая команда работала в своем ритме, бэклог быстро переполнялся задачами, а релизы не выходили вовремя. Команда вроде работала, но синхронности не было.
За один квартал мы смогли перестроить работу команды, повысить производительность на 17% и почти вдвое ускорить релизы. В этой статье я расскажу о 6 практиках, которые помогли нам прийти к такому результату.
Также с этим кейсом я выступал на конференции Agency Growth Days. Сохранил запись для тех, кто больше любит видеооформат :)
Проблемы, с которыми мы столкнулись
Вот какие проблемы возникли в нашем отделе разработки, которые, думаю, будут знакомы многим продуктовым командам:
- Разный ритм работы, который мешал прогнозировать сроки и совместно планировать задачи. Каждая команда работала в своем темпе. Никто из других команд не знал, как у остальных все устроено.
- Срывы релизов, из-за которых сдвигались задачи. Обновления никогда не выходили вовремя, по крайней мере, в запланированный срок. Либо вообще не добирались до продакшена, что еще хуже. Из-за этого страдало планирование: команда не могла приступить к новым задачам, пока не завершала предыдущие.
- Неопределенность в описаниях задач, которая приводила к недопониманиям и переделкам. Формулировки ТЗ были вроде «Сделайте, чтобы было классно». Плюс много деталей по задаче уточняли уже после того, как над ней начинали работу.
- Разросшийся бэклог, из-за которого было сложно управлять приоритетами. Задач становилось так много, что было непонятно, что стоит сделать в первую очередь — исправить баг или добавить новый функционал. Из-за этого было сложно планировать спринты и проводить груминги.
- Неслаженная коммуникация между отделами, из-за которой задачи зависали. Коммуникация между разработчиками и QA строилась на устных договоренностях, из-за чего про задачи часто забывали. Например, такие цитаты можно привести: «Не забудьте сказать тестировщикам, чтобы они начали тестировать, когда задача будет готова». Но разработчик, скорее всего, забудет. Кроме того, это лишняя нагрузка для него.
Все эти проблемы мешали команде слаженно работать и выпускать обновления вовремя. Поэтому мы решили пересмотреть процессы и выстроить систему, в которой будет больше прозрачности и предсказуемости. Далее расскажу о 6 практиках, в эффективности которых мы убедились на своем опыте.

Показатели до внедрения практик
Создание общего спринта для всех команд
У нас есть 6 команд разработки: 4 продуктовые и 2 платформенные. Все работаем по Scrum, но мы не радикальные последователи этой гибкой методологии. Соответственно, работаем тоже по спринтам.
Но одних принципов гибкой методологии недостаточно, чтобы навести порядок в работе команды. Что у нас порождало хаос:
- Нерегламентированная длительность спринтов. У одной команды спринт начинался в понедельник, у другой — в среду. Один длился неделю, другой — две, а третий мог растянуться на месяц. И все это у каждой команды по-своему.
- Несоблюдение сроков спринтов. Дедлайны задач постоянно сдвигались, и из-за этого спринты затягивались.
- Отсутствие фиксации результатов. Спринт — итерация, за которой должен следовать релиз. Но раньше мы не фиксировали результаты релизов, и из-за этого было сложно оценить прогресс.
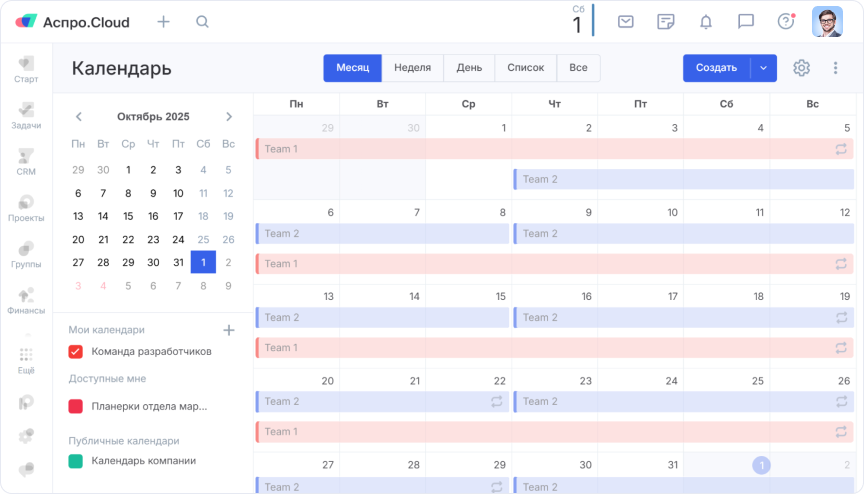
Как было раньше: все команды работали в своем спринте
К чему мы пришли? Мы ввели единый двухнедельный спринт для всех команд с фиксированными датами начала и окончания. По ходу спринта определяем дедлайны для переноса задач в тестирование и для планирования следующего спринта. Это нужно, чтобы заранее понять, что мы успеваем сделать в этом спринте, а что придется перенести на следующий.
Вот какое у нас сейчас расписание:
- 1-й понедельник — начало спринта;
- 3-й понедельник — завершение: релиз и ретроспектива.
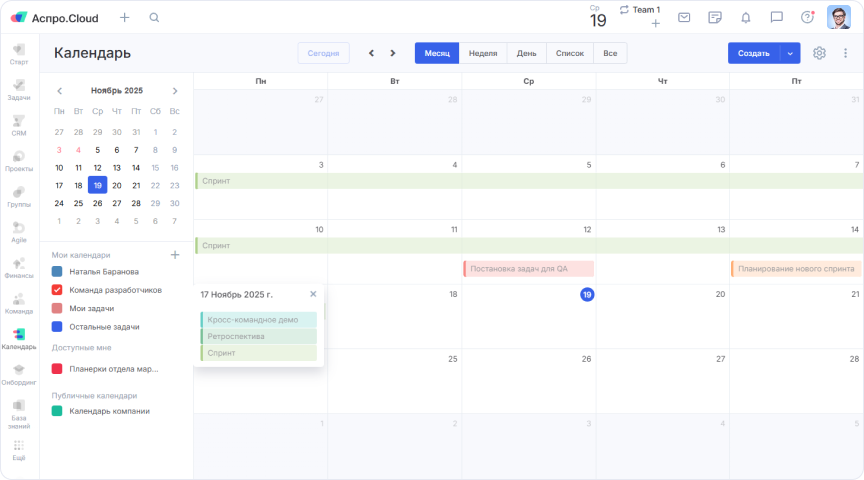
Как стало сейчас: единый двухнедельный спринт для всех команд
Также ввели кросскомандное демо. Оно публичное, на него приглашены абсолютно все. Кросскомандное демо помогает другим отделам:
- узнать, что нового сделали разработчики;
- понять, как работает новый функционал;
- задать вопросы и дать пожелания по улучшению функционала.
Как проходит демо:
- Все команды разработчиков проводят презентации. Показывают, кто что сделал за две недели, делятся результатами.
- К нам приходят маркетологи, ребята из техподдержки, руководители и даже собственники. Все слушают, всем нравится, особенно маркетологам :)
Как итог: стало очень удобно и предсказуемо. Больше никто не спрашивает: «А когда у вас релиз? Когда начинается спринт? А когда вы планируете следующий спринт?». Теперь все работают в едином ритме.


Расширение жизненного цикла задач
Раньше наша Scrum-доска включала несколько стандартных колонок:
- сделать;
- в работе;
- код ревью;
- тестируется;
- выпущено.
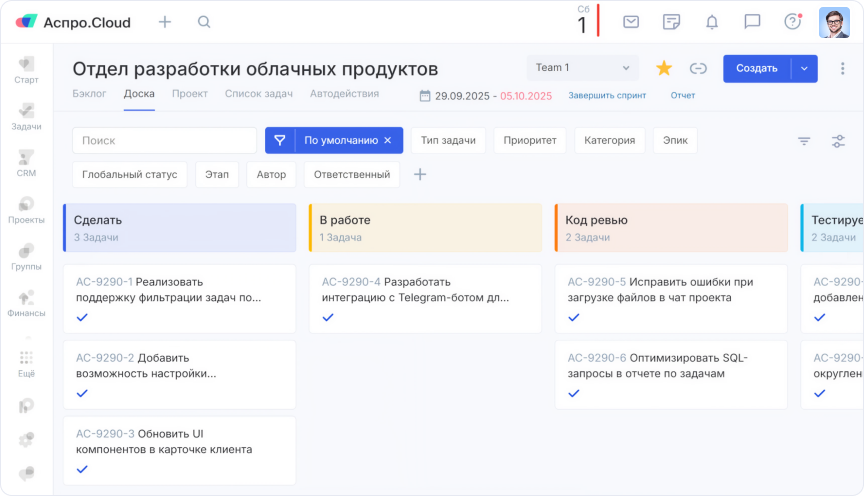
Scrum-доска отдела разработки раньше
Scrum-доска показывала общий ход задач, но не давала понимания, что происходит с задачей прямо сейчас. Например, когда разработчик сделал задачу, он переносил ее на этап «Код ревью», чтобы тимлид проверил. Я открываю доску, вижу задачу в колонке «Код ревью», но неизвестно — тимлид уже проверяет ее или она просто ждет своей очереди. Из-за этого сложно было понять, идет ли работа или задача стоит на месте.
То же самое касается отдела тестирования. Работают ли сейчас над задачей? Или она ожидает тестирования? Или уже прошла его? Это неясно.
Еще один момент — блокеры, из-за которых не было видно, что происходило с задачей раньше.
Раньше, если возникала сложность, задачу просто возвращали в колонку «Сделать». Визуально она выглядела как новая, хотя фактически над ней уже начинали работу, но остановили. Из-за этого невозможно было понять, сталкивалась ли команда с проблемами и сколько времени ушло на их решение.
Какие дополнительные этапы добавили:
- ожидает код ревью;
- пройдено код ревью;
- ожидает тестирование;
- ожидает релиза;
- на паузе.
Также разделили этап «Сделать». Теперь появился «Бэклог» — этап, на котором задача еще не описана. И «Готова к работе» — задачи, которые соответствуют Definition of Ready. Подробнее о DoR расскажу в следующем пункте.
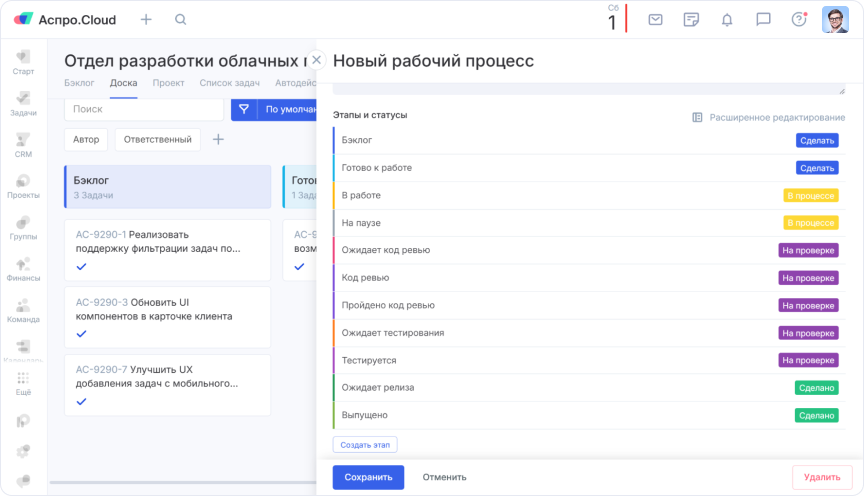
Новые этапы жизненного цикла задачи
Что дает такой рабочий процесс? Кто-то может сказать: «Ой, этапов стало слишком много, неудобно». Но на самом деле это не добавило дополнительных расходов по времени. Зато теперь у нас есть полное понимание того, где конкретно находится каждая задача и в каком она состоянии.
Также такая декомпозиция позволяет выявлять узкие места. Например, чтобы посмотреть: «Ага, у меня задача долго ожидает тестирование». На основе этой информации мы можем принимать решения. Например, как сократить время прохождения задачи до релиза.
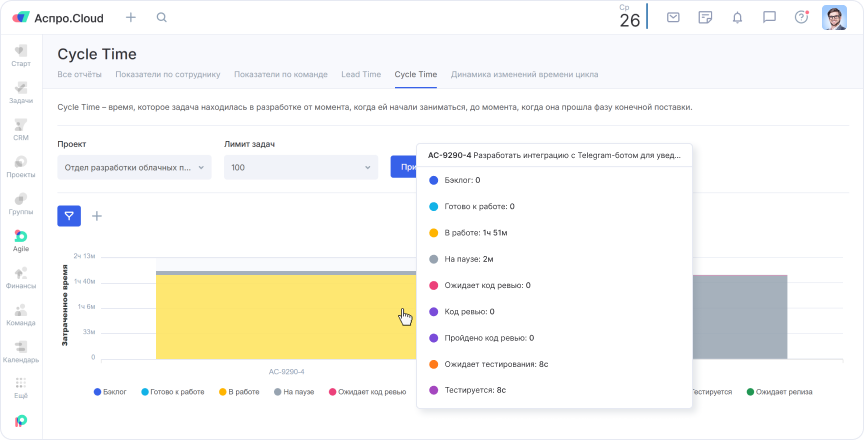
Отчет по затраченному времени на каждом этапе задачи
Подготовка задач по методике Definition of Ready
В подготовке задач долгое время сохранялся хаос. Главная проблема — задачи были плохо описаны, а реализация не была продумана. Здесь подходит фраза: «Мусор вошел — мусор вышел». Если в разработку поступал скомканный кусок описания вроде «Лови и делай», то и результат был таким же.
Вот к чему приводило плохо составленное ТЗ:
- отсутствие ясности у команды;
- частые возвраты задач на доработку;
- проблемы с планированием спринтов.
Базовые принципы DoR, которые мы ввели
1. Ясное и понятное описание задачи
Важно, чтобы все участники команды одинаково понимали поручение. Без четкого ТЗ даже простая доработка превращается в бесконечные уточнения.
Но что такое «ясное и понятное описание»? Для нас, например, хорошо работает фреймворк Jobs to Be Done. Он помогает создавать четкие и понятные описания задач.

Описание задачи по методологии Jobs to be done
Например, вместо формулировки «Добавить кнопку экспорта в Excel» лучше написать: «Когда я завершаю подготовку финансового отчета, хочу быстро выгрузить данные в Excel, чтобы передать их бухгалтеру без ручного копирования».
Такое описание помогает команде понимать контекст, ценность и результат, а не просто выполнять формальное действие.
Вот еще несколько советов, как составить описание к задаче:
- Разбейте описание на логические части. Чтобы структурировать информацию, разделите описание на блоки: сценарий и реализация.
- Используйте простые формулировки. Избегайте сложных конструкций и жаргона, пишите так, чтобы смысл был ясен без дополнительных разъяснений.
- Добавьте визуальные элементы или пояснения. Например, скриншоты, дизайн-макет с hover-эффектами и всплывающими подсказками.
2. Определена потенциальная бизнес-ценность
Каждая задача должна иметь понятную ценность для продукта и пользователя. Это позволяет команде видеть, зачем она делает именно эту доработку, и помогает руководителям корректно расставлять приоритеты.
Без этого критерия команда может тратить ресурсы на задачи, которые не влияют на развитие продукта или клиентский опыт.
3. У команды есть нужные скиллы и вся информация для решения этой задачи
Выполнима ли задача? Знает ли команда, что делать? Могут ли они сделать это сейчас? Если каких-то навыков не хватает, это приводит к блокировкам задач и потере времени. Чтобы это исправить, мы ставим задачу на исследование. Это когда разработчик ищет и изучает информацию, как можно решить задачу.
4. Задача выполнима за один спринт
Раньше крупные задачи тянулись неделями и сбивали планирование. Мы ввели правило: если задача не помещается в один спринт, ее нужно декомпозировать на части. Это помогает команде видеть прогресс, чаще выпускать обновления и поддерживать предсказуемый ритм разработки.
Автоматизация коммуникации между отделами
Наш отдел разработки тесно взаимодействует с другими командами: тестировщиками, техподдержкой, маркетологами. Раньше мы общались в чатах или просто подходили к коллегам лично, чтобы уточнить детали. Это занимало время и отвлекало от основной работы. Поэтому мы решили автоматизировать этот процесс с помощью уведомлений по пользовательским полям в нашей системе.
В задачах мы добавили поля-триггеры, например, «Нужен маркетинг». Если его включить, маркетологам автоматически приходит уведомление. Например, чтобы сделать пост-анонс по новому апдейту. Не нужно никому писать вручную.
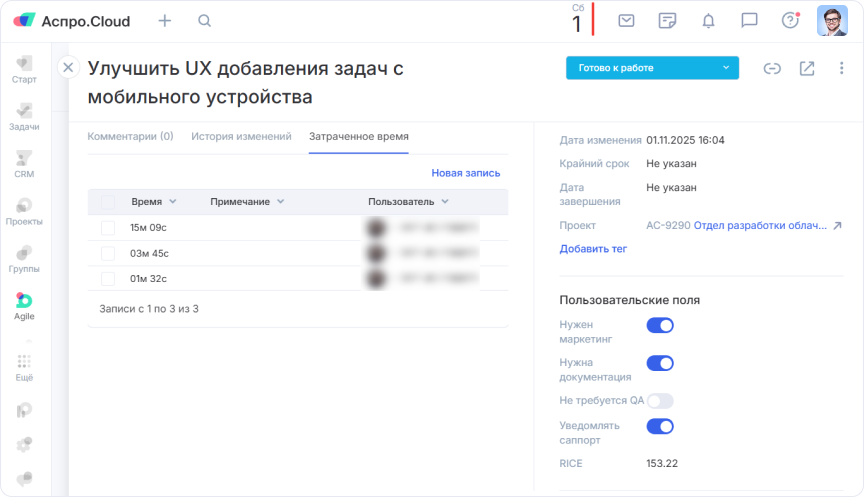
Поля-триггеры автоматических уведомлений в Аспро.Cloud
Безусловно, от коммуникации никуда не уйдешь. Но от ненужного общения вроде напоминаний «Проверь задачу» — мы избавились.
Планирование по кварталам
Раньше мы жили от спринта к спринту. Краткосрочные задачи постоянно вытесняли стратегические, и в итоге команда теряла фокус.
Чтобы навести порядок и выстроить общее видение, мы начали четко планировать работу по кварталам. Такой подход позволил соединить ежедневную операционку с долгосрочными целями и сделать развитие продукта более предсказуемым.
Какие плюсы мы для себя из этого извлекли?
- Согласование со стейкхолдерами и инвесторами. Возможность регулярно получать обратную связь от ключевых заинтересованных сторон. Чтобы потом ни у кого не возникало вопросов: «Куда идет продукт? Как вы ведете работу?».
- Квартальная ретроспектива. Регулярный анализ успехов и проблем за квартал помогает вовремя скорректировать курс и улучшить процессы.
- Четкие цели и приоритеты. Квартальные планы позволяют нагляднее понимать приоритеты задач в соответствии с продуктовой стратегией. А также определять очередность работ на их основе.
- Баланс краткосрочных и долгосрочных задач. Позволяет планировать выполнение как срочных задач, так и более значимых долгосрочных инициатив.
Приоритизация бэклога
Наш опыт работы с бэклогом был следующим: «Давайте добавим задачу в бэклог, там точно не потеряется». Но вопрос был в том, найдет ли ее разработчик, когда там уже будет несколько тысяч задач. К тому же они еще и дублируются.
Вот так у нас и раздулся бэклог — до 2 000 задач. Непонятно было, какие из них важны, а что может подождать. Из-за этого планировать спринты стало крайне сложно.

Есть разные подходы, как можно резать бэклог, когда он раздувается. Например, можно удалять задачи, которые старше одного года. Считается, что они уже не важны. Были бы важны, залетели бы по новой.
Я попробовал и посмотрел бэклог. Думал, сейчас большая часть будет действительно устаревших или уже давно выполненных задач. К моему удивлению, я обнаружил, что нет. Там есть довольно много важных задач, которые влияют на базовое качество продукта.
Чтобы такие задачи не терять и не мучаться в их поисках, мы ввели приоритизацию бэклога по методологии RICE:
- reach — охват;
- impact — влияние;
- confidence — уверенность;
- effort — усилия/трудозатраты.
Оценка с помощью RICE работает гораздо лучше, чем дискретная приоритизация с тремя уровнями: высокий, средний и низкий. Например, вы отсортировали задачи по приоритету. У вас получилось 50 задач с высоким приоритетом, 50 задач со средним и еще столько же с низким. Какая из 50 задач с высоким приоритетом важнее? Не очень понятно. С помощью RICE существенно облегчается планирование спринтов.
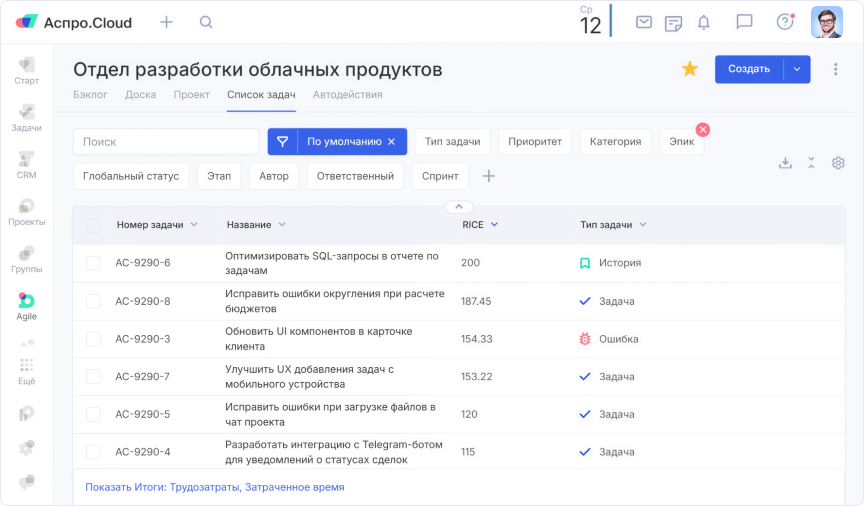
Приоритизация задач по методу RICE
Что в итоге изменилось
Какие результаты мы получили после того, как внедрили практики:

Ключевая метрика, за которую мы бились, это снизить Time-to-market. Это время прохождения задачи с этапа «Готова к работе» к «Выпущено». Оно у нас снизилось почти в 2 раза: с 23 до 11 дней. Сейчас тоже нисходящий тренд имеется.
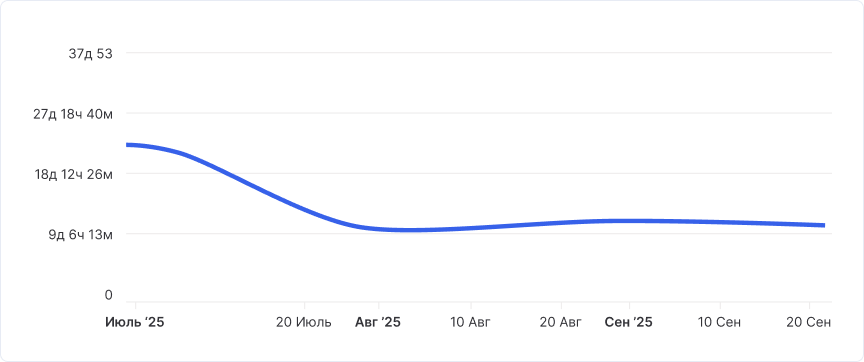
Динамика изменения времени цикла «Готово к работе» — «Выпущено»
Также снизили медианный возраст задачи с 7 до 6 месяцев.
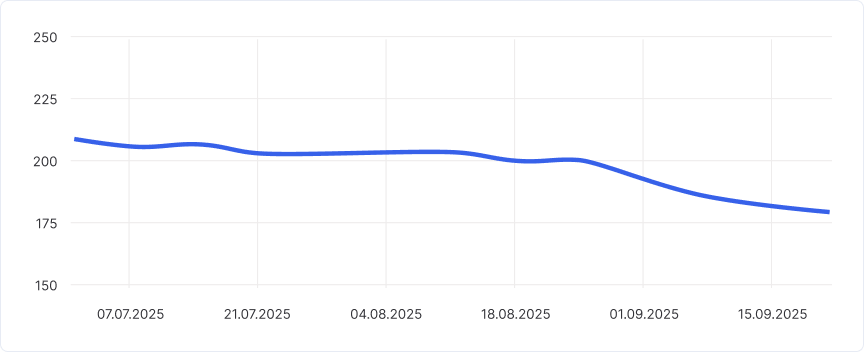
Омоложение бэклога — cнижение медианного возраста задачи
Заключение
За один квартал мы прошли путь от хаоса в процессах до четкой системы, где каждая команда понимает приоритеты и следует единому ритму. Вместо вечных срывов и потерь задач — стабильные релизы и измеримый рост.
Мы сделали процесс разработки прозрачным для всех участников и повысили производительность отдела на 17%. Эти изменения показали, что важно анализировать свои рабочие процессы и находить способы, как их можно улучшать.





